


Deep learning models, particularly large language models (LLMs), have witnessed substantial growth in size. Consequently, training such models has become more demanding in terms of resources. In this context, you have likely come across the term FLOPs (Floating Point Operations) when discussing computational complexity and performance. Understanding FLOPs is crucial, especially if you aim to estimate the computational requirements for training models. This knowledge can help you infer the training time and even anticipate the associated training costs.
In this blog entry, the goal is to demystify FLOPs by providing insights into various aspects. We will
estimate the number of FLOPs needed for training a model
explore you derive the required training time and cost
tl;dr - too long; didn't read
FLOPS (Floating point operations) are a metric to determine the complexity of Deep Learning models
FLOPS required to train a feedforward layer can be approximated with (# of parameters * 6), same approximation also roughly works for larger transformer models (per token)
A A100 GPU can usually process 312 billion FLOPS/s (Float 16), but is usually only utilized <50% due to bandwidth constraints
Having the # of total FLOPS and GPU capabilities (incl utilisation), you can approximate training time and cost (though with a lot of limitation)
What are FLOPs?
FLOPs represent the count of individual floating-point operations (an addition, multiplication, etc. of floats [numbers with decimals]) executed during a deep learning model's inference or training phase. These operations can include matrix multiplications, convolutions, activation functions, and other mathematical computations involved in processing the input data through the neural network.
Naming conventions There is some confusion in terminology around FLOPs. You often find those terms
FLOP: A single operation between floating point numbers, like multiplication or addition
FLOPs: Multiple FLOP operations
FLOPs, FLOPS, FLOPs/s: These are all sometimes used for FLOPs per second. In this article, I will be using FLOPs/s to avoid confusion.
TFLOPs stands for TeraFLOPs, where "Tera" represents the prefix for one trillion (10^12), while GFLOPs stands for GigaFLOPs, where "Giga" denotes the prefix for one billion (10^9).
FLOPs in Neural Networks: Intuition

Calculating the FLOPs in a linear layer involves looking at the matrix multiplication and the addition operations (bias) performed within the layer.
Here's a step-by-step guide (based on Figure 1) on how to calculate the FLOPs in a linear layer:
Determine the input and output dimensions:
Let's denote the input dimension as
(batch_size, in)and the output dimension as(batch_size, out), whereinrepresents the number of input features, andoutrepresents the number of output features.
Calculate the number of operations for matrix multiplication:
In a linear layer, the primary operation is matrix multiplication, where the input is multiplied by the weight matrix.
The weight matrix dimensions will be
(in, out)since each input feature needs to be multiplied by a weight value for each output feature.Compute the number of operations for a single output element
To compute the number of operations for the matrix multiplication, you first need to multiply the elements with each other, which are
inoperations. Adding the results arein-1operations. Overall, the matrix multiplication involves(in-1)+inoperations, which is often simplified as2*in.The first reason for the simplification is that for large the relative difference becomes smaller.
The second reason is that linear layers often involve a bias. Adding a bias involves
out*batch_sizeoperations. Combining bias and matrix multiplication then leads to2*inoperations in total.
Calculate the total FLOPs for the full output matrix
The output matrix has the dimensions
(batch_size, out). The overall FLOPs can be calculated bybatch_size*out*(2*in)
From those results, you can see that a forward pass for a single parameter (in a linear layer) equates to two FLOPs. In the example, we have 12 FLOPs for 6 parameters.
FLOPs in Transformer Models
Estimating the FLOPs in a transformer model can be a slightly intricate process due to the different layers within the model. The calculation of FLOPs becomes nuanced as each layer within the transformer can have a distinct configuration and computational complexity.
The FLOPs (for a forward pass) per token are calculated as follows:

where

while
d(attn) = d(ff)/4 = d(model)
Small Tip: If you want to make the calculations yourself, every huggingface model includes a config.json file where you can find those parameters.
FLOPs per backward pass
For model training, you also need to add the FLOPs for a backward pass. In “Language Models are Few-Shot Learners”, Brown et al. argue that a backward pass needs two times as many FLOPs as a forward pass. An intuitive explanation is given here.
So, if you want to approximate the number of FLOPs in a dense feedforward network, you can use 6 FLOPs per parameter (4 for backward pass, 2 for forward pass).
Estimating the FLOPs for real models Using the formula from Table 1, you can make the following calculations for a sample of models:
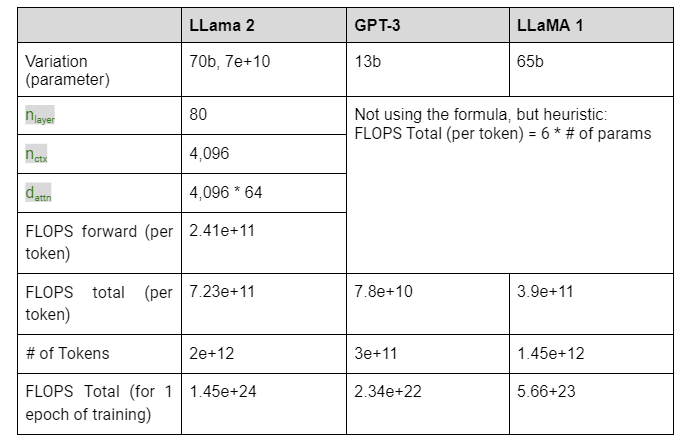
Using this heuristic gives pretty much the same answer as the actual parameter counts for GPT-3:

How many FLOPs can a GPU process?

Peak FLOPs
Normal GPU cores, often named shader cores or CUDA cores, are the primary computational units in a GPU. They are designed to handle general-purpose parallel computations and execute a wide range of graphics and compute tasks.
Tensor cores are specialised hardware units introduced in recent GPU architectures, such as NVIDIA's Volta, Turing, and Ampere. They are specifically designed to accelerate matrix operations commonly encountered in deep learning and AI workloads and can usually handle a lot more computations. For the A100, the peak performance using floating point 16 bits is 312 TFLOPs/s, while being massively less when using the CUDA cores.
Potential Bottlenecks
Three limiting factors affect potential peak performance - data transfer within the GPU, between GPUs and to other system components.
GPU memory bandwidth refers to the speed at which data can be transferred between the graphics processing unit (GPU) and its dedicated memory (VRAM). It measures the rate at which data can be read from or written to the GPU's memory.
NVLink provides a dedicated interconnect between GPUs, allowing for efficient communication and data sharing, which can be advantageous for deep learning tasks that involve parallel processing across multiple GPUs.
PCIe (Peripheral Component Interconnect Express) Gen4 is a standard interconnect technology used for connecting various hardware components, including GPUs, to the system's motherboard. It provides a high-speed data transfer path between the CPU and the GPU.
GPU Utilisation in Practice
I found an interesting article that describes how the lack of high-speed memory requires the GPU to frequently re-distribute data and thereby decreasing GPU utilisation. Two quotes describe the existing bottlenecks quite well:
Even with heavy optimizations from leading researchers, 60% FLOPS utilisation is considered a very high utilisation rate for large language model training. The rest of the time is overhead, idle time spent waiting for data from another calculation/memory, or recomputing results just in time to reduce memory bottlenecks.
Increased memory bandwidth is generally obtained through parallelism. While standard DRAM is only a few dollars per GB today, to get the massive bandwidth machine learning requires, Nvidia uses HBM memory, a device composed of 3D stacked layers of DRAM that requires more expensive packaging. HBM is in the $10 to $20 a GB range, including packaging and yield costs.
How long does it take to train a model?
If you have the total FLOPs required to train a model and know about the capabilities of your hardware, you can estimate the training time.
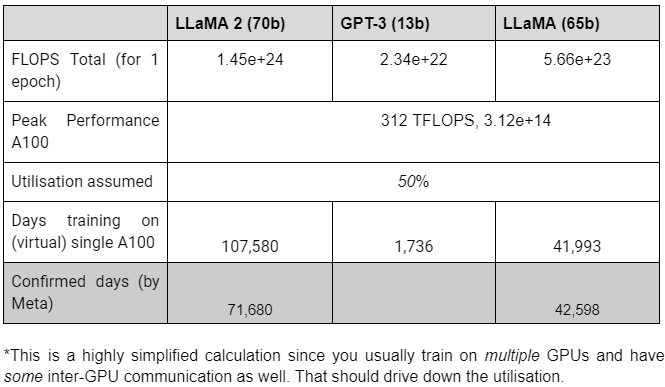
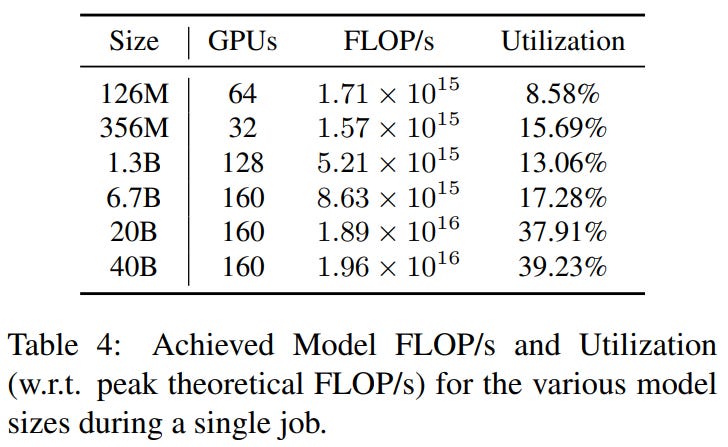
A real-life example was published in the GPT-SW3 (a Swedish LLM, mainly trained on Nordic languages) paper, where the authors got to a peak utilisation of 39,32%.:
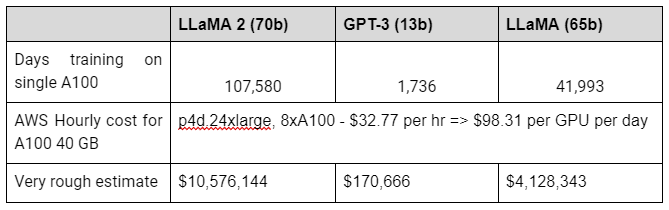
How to derive training costs?
Once you calculate the required training time, you can derive the training cost. I just did a very simple calculation, by assuming current AWS pricing. In practice, this is somewhat more complicated.
You rely on heavily simplified duration calculation.
No one training LLMs will pay the public (undiscounted) cloud, but much cheaper ones.
This calculation only considers a single, full training run. Usually, you will have to do multiple runs. Additionally, the training cost might not be the main cost driver for developing an LLM, but rather the labour cost.
Also this is only for the pre-training and does not consider fine-tuning, RLHF or anything else.
Summary
I hope this was an interesting introduction into how to calculate FLOPs for neural networks and derive training time and cost.
Luckily, my employer Schibsted is very supportive of learning and I got the time to work on the article during one of our projects. Also, ChatGPT helped a bit in shaping some of the formulations.
If you want to connect, please subscribe or add me on LinkedIn.